Abstract :
ViT (Vision transforemr)는 현재 많은 vision task에서 좋은 성능을 보여주고 있는 모델이다. 하지만 그만큼 모델의 사이즈가 커 compression이 필요한데 CNN에서 compression 방법들을 그대로 가져와 적용하면 성능이 잘 나오지 않는다고 한다. 그러면서 transformer의 self-attention이 low-pass filter이고 low-frequency signal이 ViT에서 더 중요하다는 점을 언급하며 이를 이용해 low-frequency sensitivity (LFS)와 low-frequency energy (LFE) 두 개의 metric을 만들어 channel pruning과 token pruning을 진행했다고 한다.
Introduction
기존 ViT compression의 문제점 두가지를 지적한다.
1. CNN compression 방법을 그대로 이용하면 ViT에서는 성능이 많이 하락한다.
2. ViT모델을 spatial domain에서 compression을 진행하면 noise가 있을때 compression 성능이 많이 하락한다.

따라서 Vision Transformer를 frequency domain에서 compression을 하는 방법을 고안했고 self-attention이 low-pass filter의 역할을 하며 ViT에서는 low-frequency signal이 중요하다는 점을 들어 low-freuqency component를 살리는 방식으로 comrpession을 해 좋은 성능을 얻을 수 있었다고 한다.
이를 위해 Low-frequency sensitivity(LFS) 라는 Taylor score를 베이스로 한 channel pruning criterion을 만들었다.
또한 self-attention이 low-pass filter역할을 하니까 low-frequency energy(LFE)라는 tocken의 low-frequency information을 정량화 할 수 있는 지표를 만들어 tocken pruning에 사용하였다.
Related work
1. Vision Transformer
NLP에서 transformer의 성공에 이어 vision task들에서도 vision transformer가 좋은 성능들을 보이고 있다. 많은 부분에서 CNN보다 ViT가 더 좋은 성능을 보이고 있는데 ViT는 computational cost가 매우 커 compression이 필요하다.
2. ViT Pruning
Channel pruning : Vit모델에 있는 weight, channel, head or blocks를 줄이는 방식
tocken pruning : input으로 들어가는 tocken중에 중요한 tocken만 사용하는 방식
3. Freuqency domain analysis for ViT and CNN
ViT와 CNN은 freuqency domain에서 반대로 작동한다고 한다. ViT는 low-frequency만 들어왔을 때 CNN보다 잘 작동한다고 하고 즉 low-freuqency 부분이 ViT에서 중요하다는 이야기다.
Method
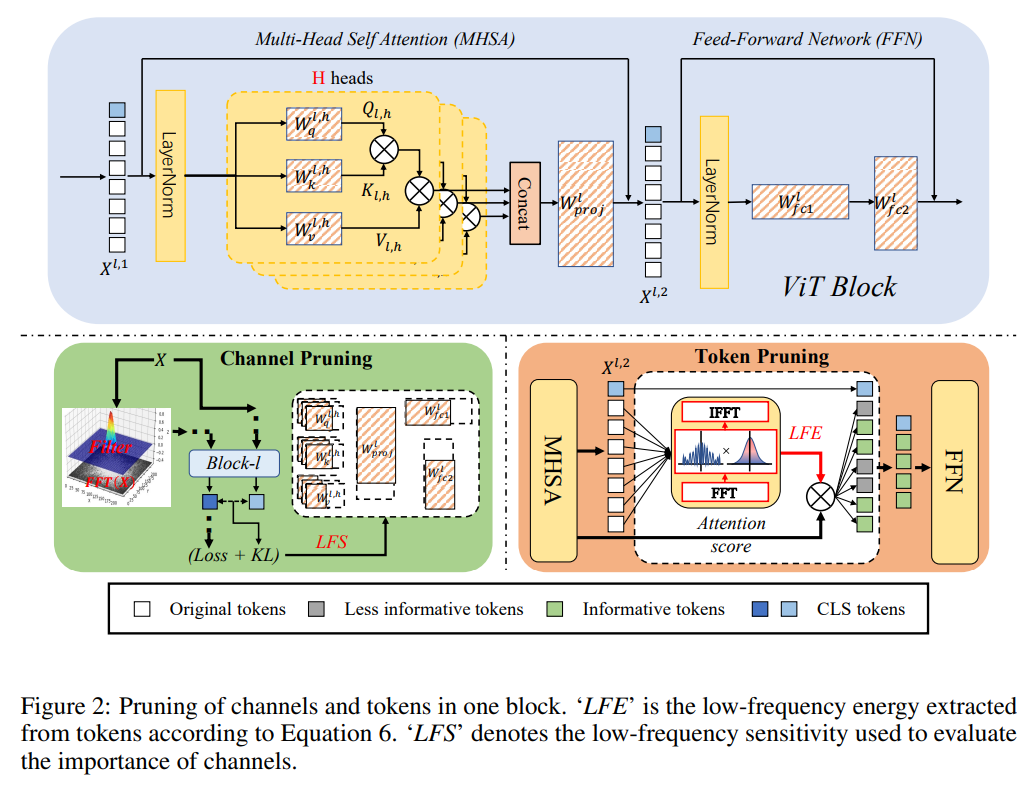
Channel Pruning based on Low-Frequency Sensitivity
위에서 계속 언급했듯이 channel과 tocken pruning에서 low-frequency에 영향을 주는 component는 남기고 나머지를 pruning해야 하는데 어떻게 그 영향을 evaluation을 할 것인지가 관건이다.
먼저 불필요한 채널을 확인하는 방법은 특정 채널을 삭제했을 때 전체 loss에 얼마나 영향을 주는지 확인해서 영향력을 evaluation 할 수 있다.

위의 식에서 X는 input, W는 weight, Y는 label이 된다. 특정 weight w를 0으로 놓았을 때 전체 loss가 얼마나 달라지는 지를 측정해서 important score I로 사용하는 방식이다.
하지만 이 방식은 전체 이미지에 대한 방식이고 계속 얘기한 low-frequency 성분에 대한 evaluation 방식은 아니다. 따라서 low-frequency 성분을 image로 분리하기 위해 low-pass filtering을 사용하여 ViT의 input으로 사용한다.

위의 식에서 X가 input이고 F함수를 통해 foureir domain으로 변환하고 low pass filter인 G와 곱해져 low-frequency 성분만 남고 다시 inverse F 함수를 통해 다시 spatial doamin으로 돌아온다. $\sigma$는 cutoff frequency가 된다.

$\tilde{X}$은 LPF를 통과한 input, $T$는 원래 이미지에서의 CLS tocken, $\tilde{T}$은 LPF를 통과한 이미지의 CLS 토큰이다.(CLS 토큰은 ViT model의 final output이다.) 왼쪽의 항으로 low-frequency input에 대한 특정 parameter의 전체 cross entropy loss에 대한 영향을 확인할 수 있고 오른쪽의 항으로 low-frequency input에 대한 특정 parameter의 토큰에 대한 영향을 확인할 수 있다. 즉 특정 parameter가 low freuqency에 대해서 영향을 얼마나 끼치는가를 확인할 수 있고 이 s값이 클수록 low-freqeuncy에 대한 영향이 크다고 할 수 있다.
하지만 수백만개의 parameter를 이런식으로 모두 scroe를 측정할 수는 없다. 따라서 first-order Taylor expansion을 사용해 approximation을 한다.

위의 식에서 미분 값들은 backward procedure에서 얻을 수 있다.

식4에서 얻은 parameter들의 important score를 채널별로 모두 합해서 각 채널의 important score를 얻을 수 있다. 이렇게 얻은 score를 바탕으로 channel pruning이 이루어진다.
Token Pruning based on Low-Frequency Energy
기존 방법들은 tocken의 realationship이나 attention score를 이용해 sample해서 골랐다. 하지만 이런 방식은 유사한 tocken들을 고르게 되고 tocken 자체에 있는 정보가 무시당할 수 있다.
이런 문제들을 해결하기 위해 Low-Freqeuncy Energy 방식을 제안한다.

위의 식에서 DC, LC는 각각 direct-current componenet와 low-frequency component이다. 즉 LPF를 통과한 이미지의 L2 norm / 원래 이미지의 L2 norm을 통해 각 tocken의 low-frequency energy를 계산한다.

위에서 계산한 low-frequency energy와 이 논문에서 제안한 CLS의 attention value를 조금 더 강조하는 식으로 수정된 attention score와 곱해서 최종 final importatnce score를 얻게 된다.

Bottom-up Cascade Pruning

위에서 설명한 LFS와 LFE criterion을 가지고 pruning을 적용하는데 Bottom-up 방식을 적용한다.
위의 그림처럼 첫번째 Block부터 시작해 LFE 정보를 이용해 Low frequency 정보가 많은 tocken을 먼저 고르고 이후에 LFS 를 이용해 low frequency에 영향을 덜 주는 덜 중요한 채널을 pruning한다. 이렇게 block을 순차적으로 pruning하여 전체 모델을 pruning하게 된다. 이는 LFS와 LFE가 이전 block의 output에 영향을 받기 때문에 이런 bottom-up 방식을 취했다고 한다. 또한 각 block마다 허용가능한 performance drop 비율을 정해두고 pruning을 하면서 일정 performance drop이 발생하면 멈추고 다음 block으로 넘어가는 방식으로 했다고 한다.
Experiments

LFS와 LFE의 성능을 확인하기 위해 다른 channel pruning sota method인 'NViT'와 Tocken pruning method 인 'EViT'와 비교한 그림이다. NViT는 Taylor score base의 channel pruning 방법이고 EViT는 attention scroe base의 tocken pruning 방식이라고 한다. Figrue 4의 a,b에 각각 결과를 그래프로 보여주었고 LFS와 LFE가 low frequency 특징을 반영하여 더 결과가 좋다는 것을 알 수 있다. (c)는 위의 식 2에서 쓰인 시그마 값으로 cutoff freuqency 값을 나타내고 0.1에서 가장 성능이 잘 나왔다고 한다.

또한 Bottom up 방식으로 Top down 방식과 거의 같은 FLOPs와 Parameter 수지만 조금 더 좋은 성능을 얻었다고 한다.
Conclusion
pruning을 frequency domain information을 활용하여 기존방법들보다 더욱 효과적으로 할 수 있음을 보였다.

