1. Introduction
Deep Learning을 활용해 노이즈를 제거하는 디노이징 모델을 학습시키기 위해서는 noise/clean pair 데이터셋이 필요하다. 이러한 데이터셋을 만드는 방법으로는 똑같은 장면에 대해 수백번 카메라촬영을 하고 평균을 내서 clean 이미지를 얻거나 synthetic한 방법으로 노이즈를 만들어 내어 이미지에 더해 데이터셋을 만들거나 한다.
제일 대표적으로 synthetic하게 노이즈를 만들어내는 방법은 가우시안 노이즈를 만들어 더하는 방식이다 (additive white gaussian noise (AWGN)). 하지만 실제 카메라로 촬영했을 때 발생하는 노이즈는 가우시안 노이즈와 항상 비슷하지 않다. 카메라의 ISP (Image Signal Processing) 과정(Gama correction, compression, and demosaicing 등)에 따라 발생하는 노이즈가 다르고 signal-dependent한 노이즈가 생긴다. 이에 대한 대안으로 ISP 과정에서 발생하는 노이즈를 고려해서 synthetic하게 노이즈를 만들기도 했다. 하지만 이 역시 사람이 직접 디자인하는 것이고 실제 발생하는 노이즈와 완벽히 같게 만들어내는 것은 매우 어렵다
Deep Learning을 이용해서 denoising을 할 때 training 데이터셋에 존재하는 노이즈에 대해서는 굉장히 잘 denoising을 하는데 training 데이터셋에 존재하지 않은 노이즈에 대해서는 굉장히 안좋은 성능을 보인다(overfitting). 따라서 가우시안 노이즈같은 노이즈만 가지고 denoising 모델을 학습시키면 가우시안 노이즈에 대해서는 굉장히 잘 denoising을 하지만 실제 노이즈에 대해서는 성능이 굉장히 떨어진다. 즉, 최대한 실제와 유사한 노이즈를 만들어내어 그러한 데이터셋으로 모델을 학습시키는 것이 denoising 성능에 큰 역할을 하고 굉장히 중요하고 어려운 일이다.
이 논문에서는 위의 문제들을 해결하고자 Generative Adversarial Network (GAN) 방식으로 노이즈를 생성하는 방식을 제안한다. 노이즈를 생성하는 generator를 학습시켜 최대한 실제와 유사한 노이즈를 만들어 denoising 모델을 학습시키고자 하는 것이다.
2. Proposed Method
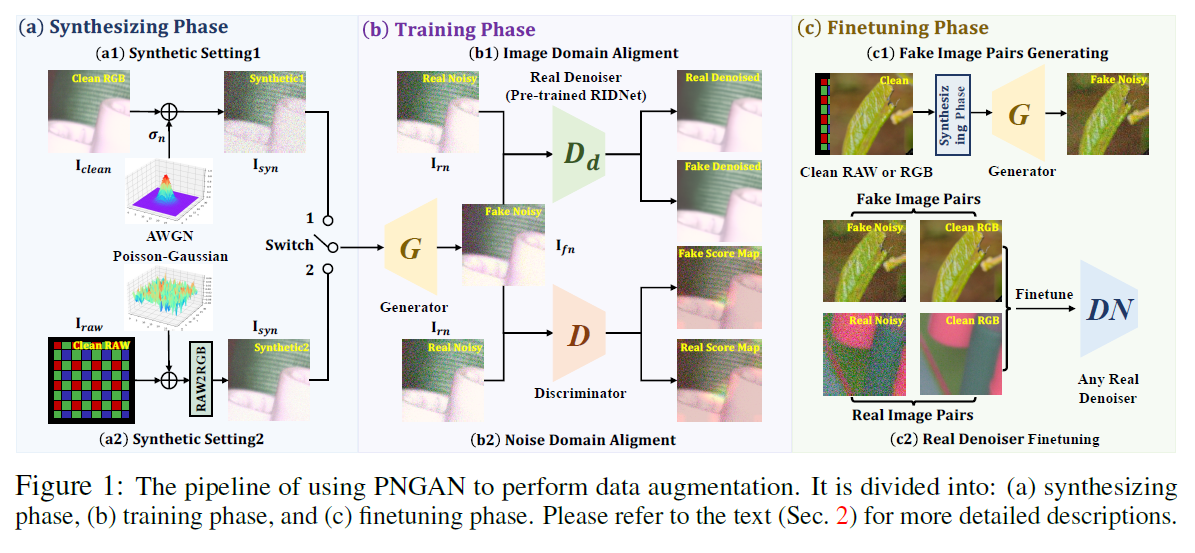
위의 Figure 1이 이 논문에서 제안한 방법의 전체 구조이다.
먼저 (a)-->(b)-->(c) 순서로 진행이 되는데 먼저 (a)에서는 clean이미지에 synthetic한 노이즈를 더해 synthetic noise 이미지를 만들어준다. clean RGB에 가우시안 노이즈를 더하거나 (a1) 아니면 clean RAW 이미지에서 Poisson-Gaussain 노이즈를 더해주고 pretrained RAW2RGB 네트워크를 통해 RGB로 만들어 노이즈 이미지가 만들어진다 (a2). 이렇게 만들어진 synthetic noisy 이미지를 input으로 받아서 Generator모델이 fake noisy 이미지를 만들어낸다.
(b)에서는 노이즈를 생성하는 generator 모델을 학습시킨다. 두가지 방식으로 generator를 학습시키는데 pre-trained denoiser 모델을 이용하는 (b1) 방식, Discriminator를 이용하는 (b2) 방식이 있다. (b1)방식을 자세하게 설명하면, generator를 통해 생성된 fake noisy 이미지와 원래의 real noisy 이미지를 pretrained denoiser 모델에 각각 input으로 줘서 clean output을 얻어낸다. 이 두 clean output 이미지에 L1 loss를 줘서 geneartor를 학습시키는 것이다. 이러한 방식을 사용하는 이유는 noise를 random하게 생성하기 위해선 fake noisy 이미지와 real noisy 이미지에 바로 L1 loss를 줄 수 없다는 것이다. 반면 output에 L1 loss를 주면 pretrained-denoiser가 노이즈를 잘 제거하는 real한 노이즈를 잘 만들수 있도록 학습이 될 수 있다. 이런 방식으로 만든 식은 아래와 같다.

(b2) 방식은 Deiscriminator를 사용하는 방식이다. 논문제목이 Pixel level noise aware인 이유가 여기 있다. 이 discrimator는 아래와 같이 noise이미지를 input으로 받고 각 pixel별로 real noise pixel인지 fake noise pixel인지를 구별하는 역할을 한다.

Generator는 이 discriminator가 real과 fake noise를 구별하기 어렵도록 noise를 생성하도록 학습이 되고 discriminator는 두 real과 fake noise를 구별하도록 학습이 된다. 전형적인 GAN의 학습방식을 따르고 discriminator와 generator에 대한 loss는 각각 아래와 같아진다.

마지막으로 (c)방식을 통해 denoising 모델을 finetuning하는 과정이다. 여기서 noise/clean pair 데이터를 만들기 위해 (a),(b) 과정을 통해 학습된 generator를 이용한다. 하지만 그냥 clean 이미지를 generator에 input으로 주면 generator는 매번 동일한 noise를 생성해버린다. 이를 해결하기 위해 (a)에서 한것과 같이 clean image에 랜덤으로 가우시안 노이즈를 더하고 이를 generator의 input으로 준뒤 realistic한 노이즈를 생성한다. 실제로 (b)에서 generator를 학습할때 input으로 가우시안 노이즈가 추가된 이미지를 받았기 때문에 문제가 없다. 사용한 generator 모델은 Simple Multi-scale Network (SMNet)으로 아래와 같고 매우 작게 만들었다고 한다.

마지막으로 총 training loss이다.

VGG를 이용해서 perceptual loss까지 추가로 넣어서 geneator학습에 사용한다. pretrained-denoiser를 통과한 real noise와 fake noise의 두 output이 같게 해주는 역할로 위에 언급한 L1 loss와 비슷한 역할을 하게 된다. 따라서 최종적으로 위에서 언급한 L1 loss, percepture loss, discriminator와 generator를 위한 loss가 모두 더해져 최종 loss가 된다.
3. Experiment
3.1 setup
먼저 pretrained-denoiser를 만들기 위해 SIDD train dataset으로 denoising 모델을 학습시킨다. 이후 generator를 같은 SIDD train 데이터셋을 이용해 학습시킨다(Figure 1. a,b). 이후 denoising모델을 fintuning 할때(Figure 1.c) DIV2K, Flickr2K, BSD68, Kodak24 and Urban100 이 데이터셋들을 이용해 fake noise/clean dataset을 만들어 내고 SIDD train dataset과 함께 denoising모델을 finetuning 한다.
3.2 Quantative results

PNGAN 방식을 적용해 RIDNet, MPRNet, MIRNET 등등 모두 real-noise 데이터셋에서 성능을 끌어올릴 수 있었다.

S1은 setting1로 가우시안 노이즈만 이용해 training을 한것이고 S2는 setting2로 ISP 과정을 고려하여 noise를 design해서 training은 한것이다(CycleISP). 거기에 각각 PNGAN 방식을 추가해서 결과를 얻어낸 것이고 성능이 확실히 올라가는 것을 확인할 수 있다.
3.3 Qualitative results

SIDD, DND, Poly U, Nam 데이터셋에서 실제 노이즈와 PNGAN으로 생성한 노이즈와 비교한 결과인데 real noise와 굉장히 유사한 noise를 생성했음을 볼 수 있다.